学习笔记_25_03_17
学习笔记_25_03_17
P11003 [蓝桥杯 2024 省 Python B] 蓝桥村的真相
题目描述
在风景如画的蓝桥村, 名村民围坐在一张古老的圆桌旁,参与一场思想
的较量。这些村民,每一位都有着鲜明的身份:要么是誉满乡野的诚实者,要么是无可救药的说谎者。
当会议的钟声敲响,一场关于真理与谬误的辩论随之展开。每位村民轮流发言,编号为 的村民提出了这样的断言:坐在他之后的两位村民——也就是
编号 和 (注意,编号是环形的,所以如果 是最后一个,则 是
第一个,以此类推)之中,一个说的是真话,而另一个说的是假话。
在所有摇曳不定的陈述中,有多少真言隐藏在谎言的面纱之后?
请你探索每一种可能的真假排列组合,并计算在所有可能的真假组合中,
说谎者的总数。
输入格式
输入的第一行包含一个整数 ,表示每次输入包含 组数据。
接下来依次描述 组数据。
每个数据一行包含一个整数 ,表示村落的人数。
输出格式
输出 行,每行包含一个整数,依次表示每组数据的答案。
输入输出样例 #1
输入 #1
1 | |
输出 #1
1 | |
说明/提示
对于 的评测用例,。
对于 的评测用例,。
对于所有评测用例,。
样例解释
在样例中,可能的组合有「假,假,假」「真,真,假」「真,假,真」「假,
真,真」,说谎者的总数为 。
解决方案
和P10900 [蓝桥杯 2024 省 C] 数字诗意类似,这也是一道数据规模巨大无比的题,达到10的18次方。根据笔者截至目前的经验,这种数据规模的题目在蓝桥杯中考察的并不是对时间复杂度的优化,而是暗示这道题目中一定隐藏着某种十分简单的数学规律,足以使得做题家们秒杀。
以此题为例:

不难发现,除了第三种情况之外,其它三种情况均为以一个含有两个1一个0的最小单位进行循环的。即。有三种情况每三位中都有一个说谎话的村民,count = n / 3,而另一种下所有人都在说谎, count = n。
故在题目要求考虑所有情况的情况下,总数为(n / 3) * 3 + n = 2n。
此外,如果串的长度不为3的倍数的时候,例如为1011的时候,按照题目首尾相连的要求,不难发现这个串是不合法的,其它情况同样如此,因此当n不为3的倍数的时候,所有人都是说谎者。
因此,解决代码如下:
1 | |
P11002 [蓝桥杯 2024 省 Python B] 神奇闹钟
题目描述
小蓝发现了一个神奇的闹钟,从纪元时间( 年 月 日 )开始,每经过 分钟,这个闹钟便会触发一次闹铃(纪元时间也会响铃)。这引起了小蓝的兴趣,他想要好好研究下这个闹钟。
对于给出的任意一个格式为 yyyy-MM-dd HH:mm:ss 的时间,小蓝想要知道在这个时间点之前(包含这个时间点)的最近的一次闹铃时间是哪个时间?
注意,你不必考虑时区问题。
输入格式
输入的第一行包含一个整数 ,表示每次输入包含 组数据。
接下来依次描述 组数据。
每组数据一行,包含一个时间(格式为 yyyy-MM-dd HH:mm:ss)和一
个整数 ,其中 表示闹铃时间间隔(单位为分钟)。
输出格式
输出 行,每行包含一个时间(格式为 yyyy-MM-dd HH:mm:ss),依
次表示每组数据的答案。
输入输出样例 #1
输入 #1
1 | |
输出 #1
1 | |
说明/提示
对于所有评测用例,,保证所有的时间格式都是合法的。
解决方案
收录这个题主要是想要记录一下Python中datetime库的使用:
1 | |
P10901 [蓝桥杯 2024 省 C] 封闭图形个数
题目描述
在蓝桥王国,数字的大小不仅仅取决于它们的数值大小,还取决于它们所形成的“封闭图形”的个数。
封闭图形是指数字中完全封闭的空间,例如数字、、、、 都没有形成封闭图形,而数字 、、、 分别形成了 个封闭图形,数字 则形成了 个封闭图形。值得注意的是,封闭图形的个数是可以累加的。例如,对于数字 ,由于 形成了 个封闭图形,而 形成了 个,所以 形成的封闭图形的个数总共为 。
在比较两个数的大小时,如果它们的封闭图形个数不同,那么封闭图形个数较多的数更大。例如,数字 和数字 ,它们对应的封闭图形的个数分别为 和 ,因此数字 小于数组 。如果两个数的封闭图形个数相同,那么数值较大的数更大。例如,数字 和数字 ,它们的封闭图形的个数都是 ,但 ,所以数字 小于数字 。如果两个数字的封闭图形个数和数值都相同,那么这两个数字被认为是相等的。
小蓝对蓝桥王国的数字大小规则十分感兴趣。现在,他将给定你 个数 ,请你按照蓝桥王国的数字大小规则,将这 数从小到大排序,并输出排序后结果。
输入格式
输入的第一行包含一个整数 ,表示给定的数字个数。
第二行包含 个整数 ,相邻整数之间使用一个空格分隔,表示待排序的数字。
输出格式
输出一行包含 个整数,相邻整数之间使用一个空格分隔,表示按照蓝桥王国的数字大小规则从小到大排序后的结果。
输入输出样例 #1
输入 #1
1 | |
输出 #1
1 | |
说明/提示
【样例说明】
对于给定的数字序列 ,数字 的封闭图形个数为 ,数字 的封闭图形个数为 ,数字 的封闭图形个数为 。按照封闭图形个数从小到大排序后,得到 。
由于数字 和数字 的封闭图形个数相同,因此需要进一步按照数值大小对它们进行排序,最终得到 。
【评测用例规模与约定】
对于 的评测用例,,。
对于所有评测用例,,。
解决方案
这道题的思路挺明确的,可以使用一个字典来存储一个数字本身的值和其对应的封闭图形个数,然后分别作为第一关键字和第二关键字进行排序输出即可。
1 | |
但是结果是这道题爆红了,主播喜提0分…
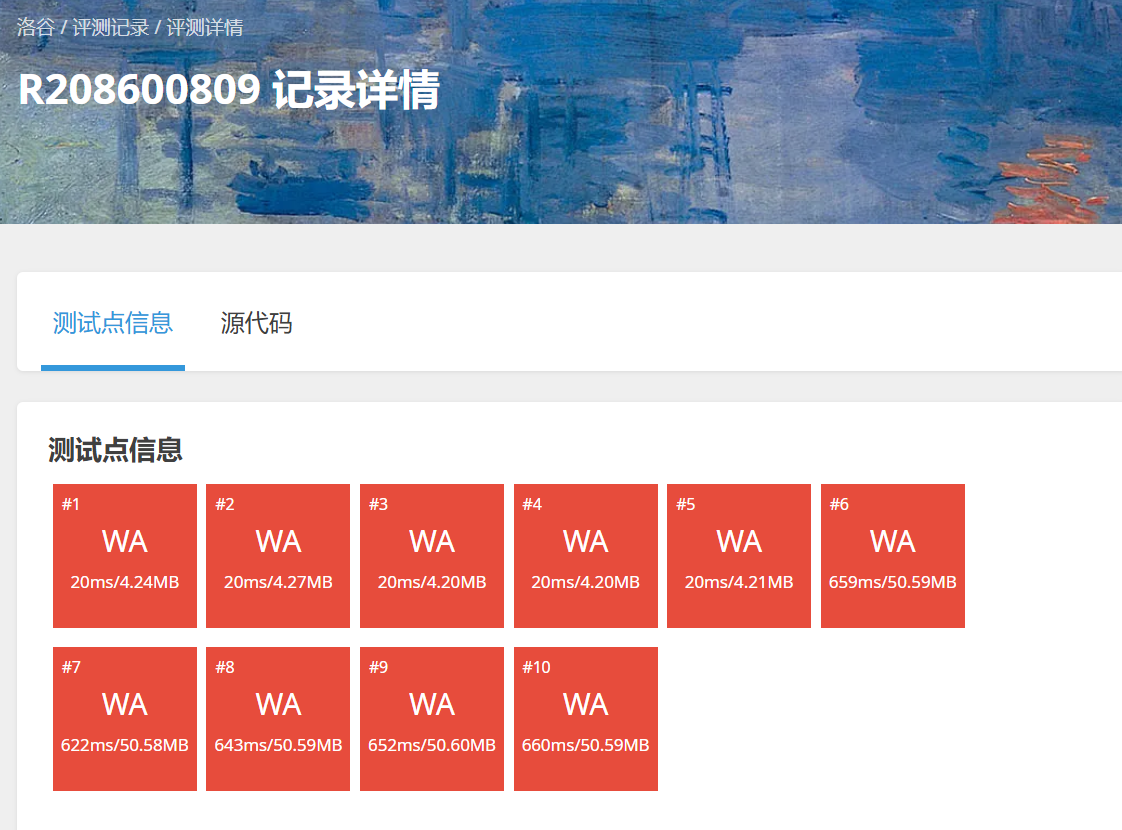
1.字典去重问题:字典的键是数字本身,当输入中存在重复数字时,后续相同数字的计算会覆盖之前的记录。例如,输入 18 18 会被存储为 {18: 2},导致输出时只保留一个 18。
2.排序结果缺失元素:最终输出基于字典的键(去重后的数字),而非原始输入的所有元素,导致输出数量与输入不一致。
因此解决方案就应该是动态地进行排序,使每一个输入都有一个对应的输出:
1 | |
最后成功AC!