软件设计师 上午题 程序设计语言
软件设计师 上午题 程序设计语言
程序设计语言是为了书写计算机程序而人为设计的符号语言,本节主要介绍程序设计语言的基本概念、基本成分和一些有代表性的程序设计语言。
一、程序设计语言的基本概念
Ⅰ 低级语言和高级语言
- 低级语言:面向机器的语言,即机器语言和汇编语言。
- 机器语言:机器语言是最基本的计算机语言,也就是我们在计算机系统章节中常常提起的机器指令,由01组成。使用机器语言设计的程序可读性很差,因此也难以维护。
- 汇编语言:人类并不能像机器一样直接读取01,因此人们就想出了一种办法:使用容易记忆的符号来代替01序列,比如用
ADD来表示加法等。这些符号表示的指令即为汇编指令,进而可以构成汇编语言。
- 高级语言:面向各类应用的程序设计语言,这类语言和人们使用的自然语言很接近,如主流的Java、Cpp和Python等。
Ⅱ 语言的翻译
显然计算机不可能直接理解汇编语言和高级语言,因此执行这类语言时就需要翻译,基本方式有汇编、解释和编译。
- 汇编:如果源程序是用汇编语言编写的,则需要一个汇编程序将其翻译成目标程序后才能执行。
- 解释和编译:如果源程序是用某种高级语言编写的,则需要对应的解释程序或者编译程序对其进行翻译:
- 解释程序:边解释边执行,不生成独立的目标代码,每次运行都需要解释器实时翻译。
- 编译程序:将源代码一次性转换为目标机器代码(如二进制可执行文件),生成独立的可执行程序。
二、语言处理程序基础
语言处理程序即为前文所述的翻译程序,它们将高级语言或汇编语言编写的程序翻译成某种机器语言程序使其可在计算机上运行。备考中我们重点要掌握的是编译程序的基本原理。
Ⅰ 编译程序的基本原理
编译程序的功能是将某高级语言书写的源程序翻译成与之等价的目标程序(汇编语言或机器语言)。其工作过程如下图所示:
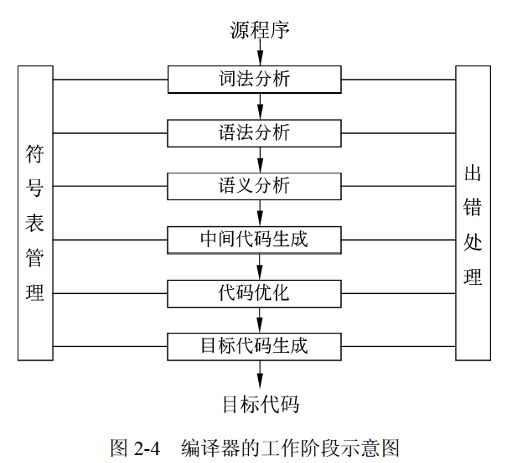
1. 词法分析
词法分析是编译器的第一个阶段,其核心任务是将源代码的字符序列转换为有意义的词法单元(Token)序列,也即记号流,为后续的语法分析提供结构化输入。
其中,每个Token常以二元组的方式输出,即<Token Type, Value>。常见的Token Type有关键字、标识符、常数、运算符和分隔符等。
比如有这样一串C语言代码:
1 | |
那么在进行词法分析后输出的Tokens就应该为:
1 | |
进行词法分析可以跳过空格、换行、注释等不影响程序逻辑的字符,并将连续的字符组合成有意义的单元(如变量名x、数字42),有效简化了后续的语法分析。
2. 语法分析
语法分析是继词法分析之后的第二个关键阶段,其核心任务是将词法分析生成的Token序列转换为结构化的语法树,以验证整个输入串是否构成一个语法上正确的程序。
如果源程序中没有语法错误,这一阶段就能正确地构造出一个语法树,否则就会指出源程序的语法错误并给出相应的诊断信息。
例如上文中的Tokens就能被构造出这样一个语法树:
1 | |
3. 语义分析
语义分析是继词法分析和语法分析之后的第三个关键阶段。它的核心任务是检查源代码是否符合语言的语义规则,确保程序在逻辑上是正确的,不会出现类似于“猫吃代码”的谬误,而不仅仅是语法正确。
例如,整除取余运算符只能对整型进行运算,若其运算对象中有浮点数就可以认为存在类型不匹配的错误。
4. 中间代码生成
中间代码生成是编译器的核心阶段之一,位于前端(词法/语法/语义分析)和后端(目标代码生成与优化)之间。它的任务是将语义分析后的语法树转换为一种与机器无关的中间表示(IR),可以将不同的高级语言转换为同一种中间代码,使其具备了跨平台的能力,为后续优化和目标代码生成提供了统一接口。
常见的中间代码有:后缀式、三地址码、三元式、四元式和树(图)等形式。
5. 目标代码生成
目标代码生成是编译器工作的最后一个阶段,这一阶段的任务即为将中间代码变换为特定机器上的指令代码。由于是生成特定机器上的代码,这一阶段的工作与具体的机器密切相关。
1 | |
编译过程中的中间代码生成和代码优化不是必须的,可省略。
Ⅱ 词法分析中的模型
正如前文所述,词法分析是一个将源程序中的字符串转换为单词符号序列的一个过程,而这个过程所依赖的模型有以下几个:
1. 正规式与正规集
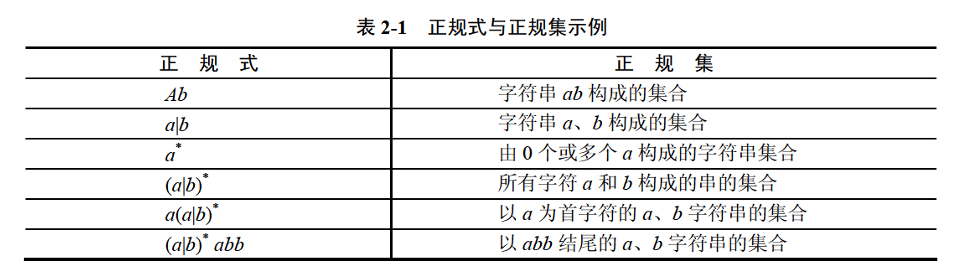
正规式是一种用于描述字符串模式的形式化表达式,用于匹配符合特定规则的字符串集合,是定义正规集的数学工具。
例如有一个正规式a*,它就定义了一个正规集{ε, "a", "aa", "aaa", ...};再比如正规式(a|b)*定义的正规集就是{ε, "a", "b", "aa", "ab", "ba", "bb", "aabba", "babab", ...}。
2. 有限自动机
有限自动机是一种用来识别正规集的抽象计算模型,又可以继续分为确定的有限自动机和不确定的有限自动机两类:
- 确定的有限自动机(Deterministic Finite Automata, DFA):对每一个状态来说识别字符后转移的状态是唯一的。
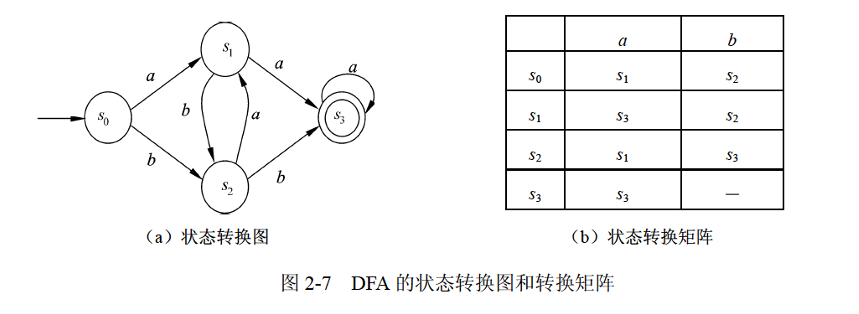
有限自动机中所谓的状态转移图和状态转移矩阵的概念和在数电中学习过的状态图基本类似,只是需要注意的是双圈表示的结点是终结结点。
- 不确定的有限自动机(Nodeterministic Finite Automata, NFA):对每一个状态来说识别字符后转移的状态是不确定的。
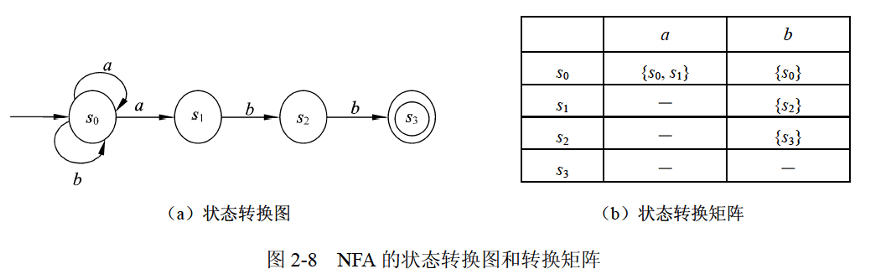
当一个字符串被输入进有限自动机中之后,如果在最后一个字符被输入之后,自动机的状态落到了双圈的终结结点上,该自动机就会返回一个“接受”的状态,说明这个字符串满足目标语言的规则,反之就会返回一个“拒绝”的状态。
也就是说,在有限自动机当中,所谓的终结结点并不是说自动机在进入这一状态之后就会终止,而是在终止时据此返回结果。
Ⅲ 语法分析中的模型
语法分析中所要用到的一个重要模型是上下文无关文法,程序设计语言的绝大部分语法规则可以采用上下文无关文法进行描述。
一个上下文无关文法可以由以下几部分组成;
- 非终结符:可进一步展开的表示语法结构的抽象符号,一般用大写英文字母表示。
- 终结符:组成语言的基本符号,一般用小写英文字母表示。
- 产生式规则:定义非终结符如何展开为终结符和非终结符的组合。
- 开始符号:语法推导的起点。
比如以下这道例题:

其中类似于T -> F|T*F就是一条产生式规则,定义了在非终结符T的展开规则。
Ⅳ 解释程序的基本原理
正如前文所述,编译程序可分为:词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成六个部分。而对于解释程序而言,有前三个过程即可。即编译器和解释器都不能省略词法分析、语法分析和语义分析三个阶段且顺序不可交换。
Ⅴ 真题赏析

C,语义分析阶段只能发现静态错误,动态语义错误只有在程序运行时才能发现。
1 | |

D,B选项的错误在于应该为在语法分析阶段可以发现程序中的所有语法错误,而非所有错误。

D,寄存器分配是目标代码生成阶段的核心任务之一,这是由于将中间代码转换为机器码时需要分配物理寄存器。

A,词法分析和语法分析的核心区别在于前者是检查字符是否符合规定而后者是检查语句是否符合规定。

B,类型检查是语义分析阶段的核心任务之一,进行类型检查可以确保程序在逻辑上正确,避免出现对浮点数进行模运算等错误情况。

B,对于A选项而言,0*有可能为空串,其开头和结尾也有可能是1。
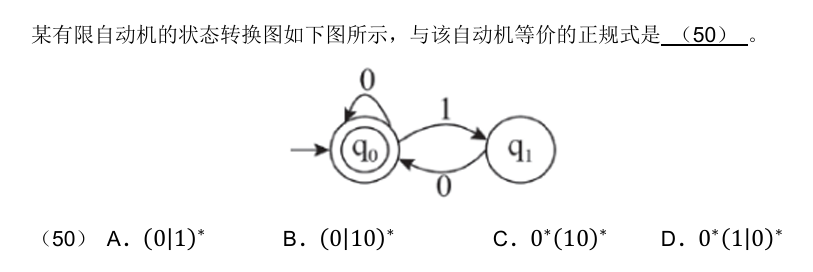
B,从题中的自动机可分析出,初态q0同时是终态,从q0到q0的弧(标记 0)表明该自动机识别零个或多个0构成的串,路径q0→q1→q0的循环表明“10”的多次重复,因此该自动机识别的字符串是“010”的无穷多次,表示为(0|10)*。