机器学习基础
机器学习基础
参考资料
- 【機器學習2021】卷積神經網路 (Convolutional Neural Networks, CNN)
- ML Lecture 21-1: Recurrent Neural Network (Part I)
- [TA 補充課] Graph Neural Network (1/2) (由助教姜成翰同學講授)
- [TA 補充課] Graph Neural Network (2/2) (由助教姜成翰同學講授)
- LSTM - 长短期记忆递归神经网络
一、卷积神经网络 (Convolutional Neural Network, CNN)
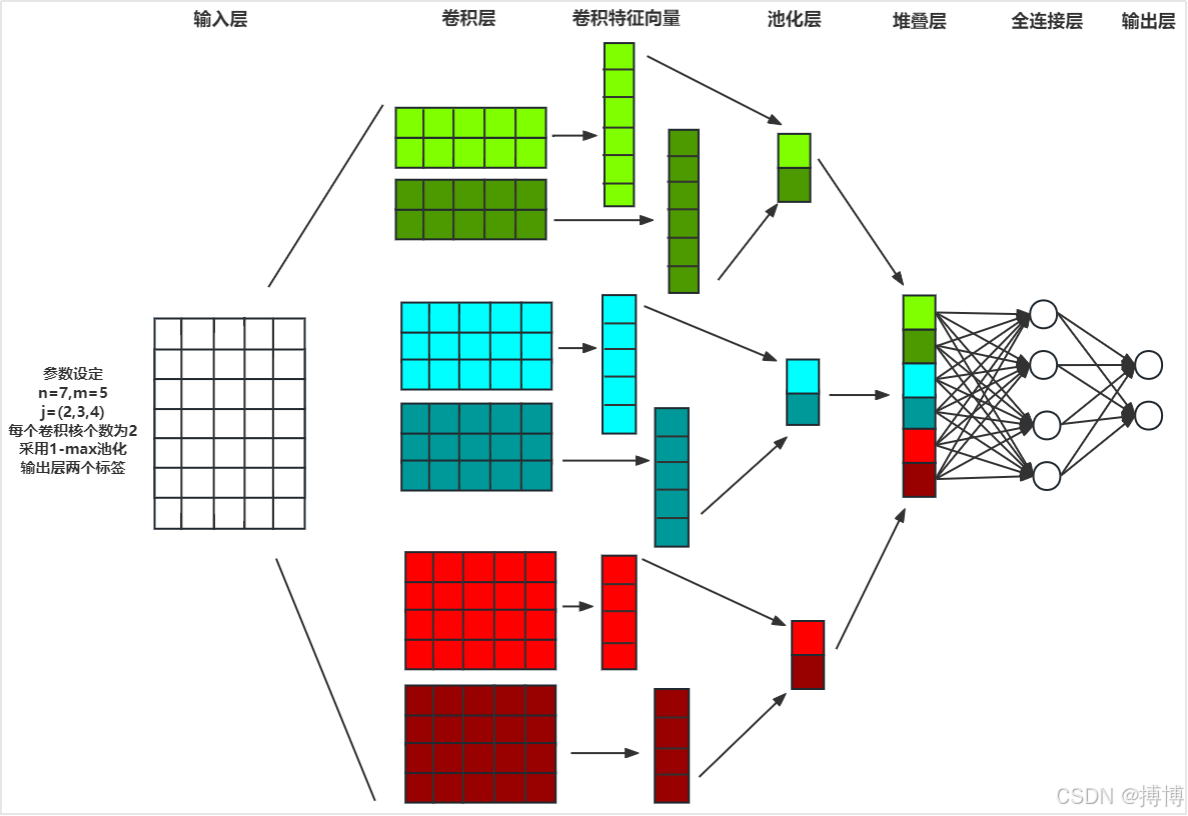
卷积神经网络可以从两个方面来理解:
1. Neuron Version
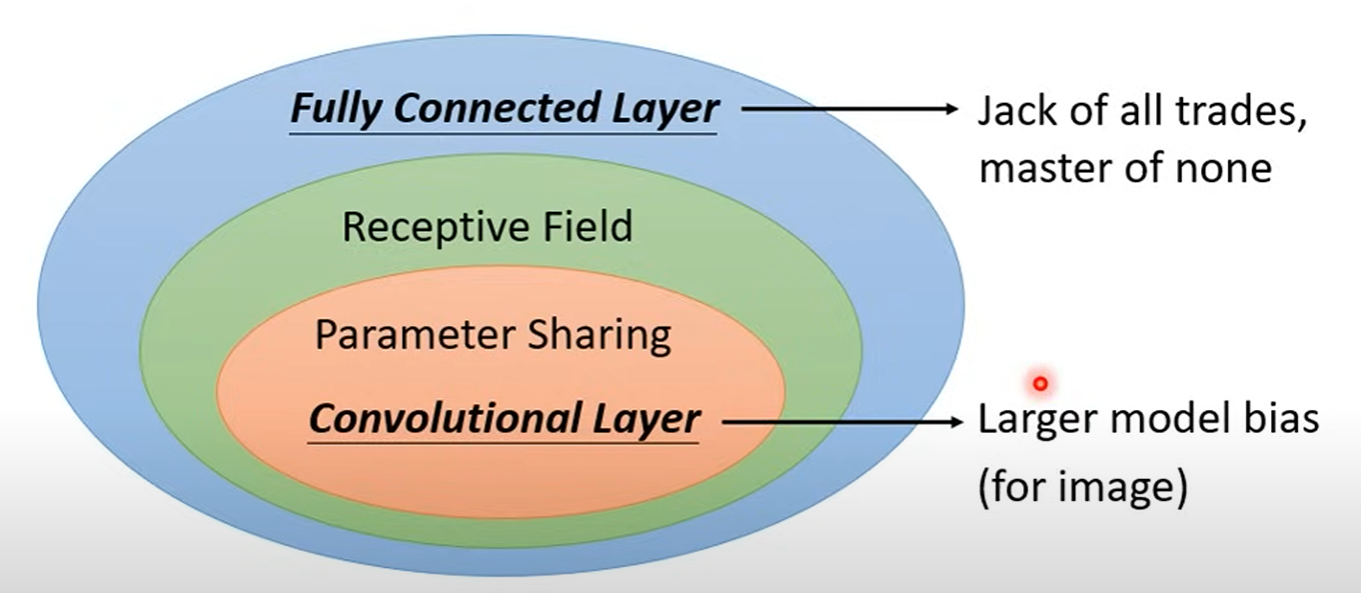
这种方法是从神经元的角度来解释卷积层的构成。首先,所谓神经元就是神经网路中的基本计算单元,在全连接层(Fully Connected Layer)中,每个神经元与前一层的所有神经元相连,也就是说,每个神经元都要对整张图像进行计算,这显然是大大增加计算量的。所以我们首先要为每个神经元分配一个合适的感受野(Receptive Field),每个神经元只负责计算自身感受野范围内的图像,这就增强了模型的效率。但是我们还不得不考虑的事情是,不同目标的相同特征不可能出现在完全相同的地方,也就是说它们很有可能出现在不同神经元的感受野中。但是它们所需的计算参数又显然是相同的,因此我们可以使这些不同的神经元共享参数(Parameter Sharing),使得同一特征可能出现在输入的不同位置,但都可以被神经元检测到。那么在这两个优化的基础上,我们就得到了将全连接层优化为了卷积层,神经元也即演变为了卷积核(Filter/Kernel)。
2. Filter Version
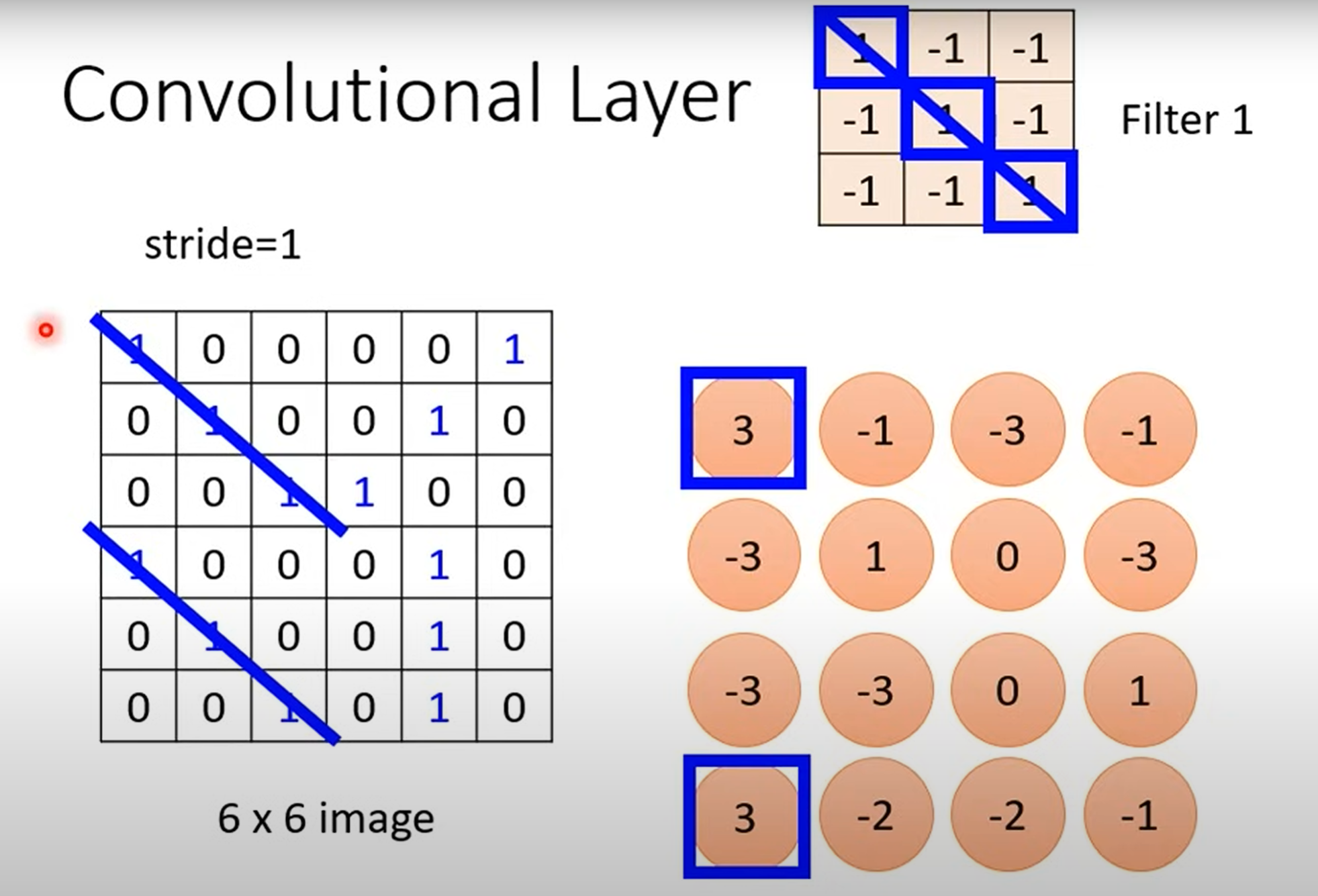
在这个版本的解释中,卷积层是由很多个卷积核(Filter)组成的。每一个卷积核的通道数(Channel)和待处理图像的通道数都是相同的,但是它们又只专注于某一个特定的特征。每一个卷积核通过微小的步长(Stride)移动遍历整个图像,最终就得到了一个特征图(Feature Map),如下图所示。多个卷积核并行处理输入,生成多通道特征图,每个通道对应不同特征的检测结果。随后,这些特征图作为下一层的输入,由新的卷积核进一步提取更高阶的特征。
此外,在CNN中还涉及池化(Pooling)和展平(Flatten)等操作。
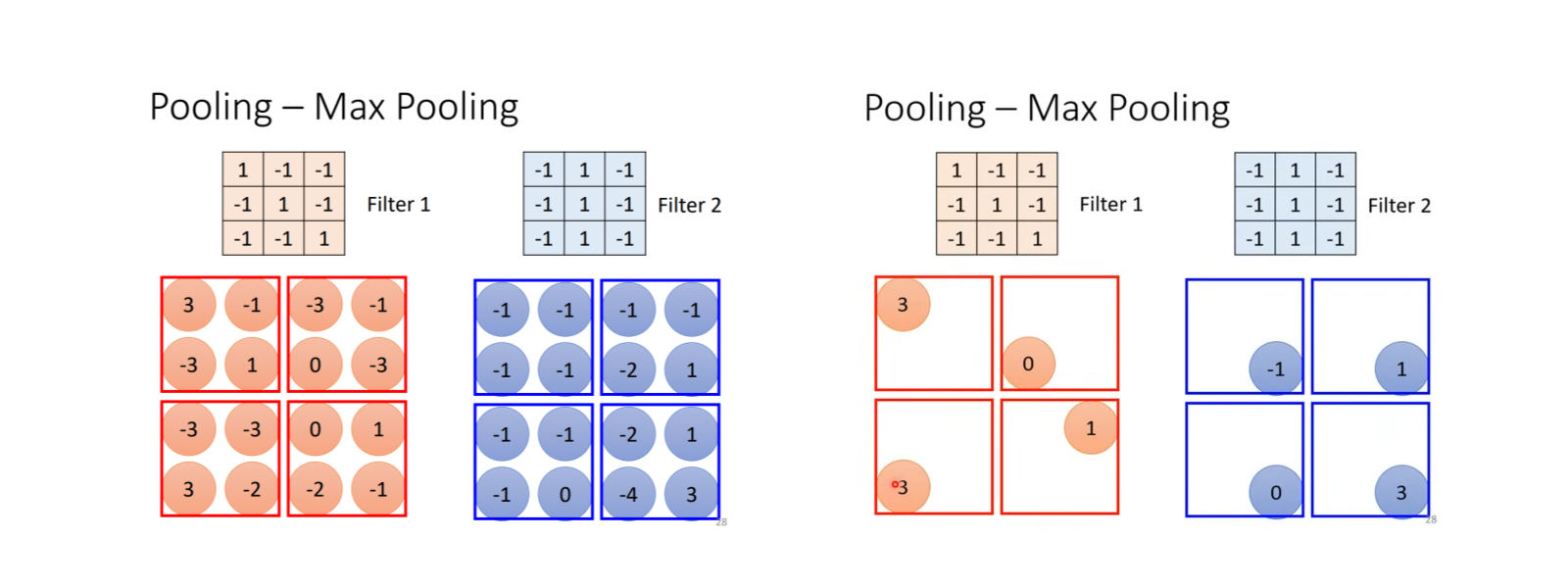
所谓池化,就是一种压缩特征图的空间尺寸、减少参数量,同时增强模型对局部微小变化的鲁棒性的方法。它可以将特征图按某种规则缩小,例如下图表示的就是一种只保留特定区域内最大值的池化方法(Max Pooling)。
而展平则是一种将多维数据转换为一维向量的操作,主要用于连接卷积层/池化层与全连接层。这是因为全连接层的神经元需固定长度的输入,而卷积层输出的特征图是3D结构,必须展平后才能匹配。
最后,全连接层通过将展平后的多维特征图与所有神经元进行全局加权连接,实现从局部特征到高层语义的映射,输出判定结果。
二、循环神经网络 (Recurrent Neural Network, RNN)
显而易见,在人脑处理一段信息的时候一定是一个连续的过程,比如看视频的时候不可能是一帧一帧地去看,否则在一些场景下就不能获取正确的信息。比如我们想要知道别人旅行的目的地,如果对方说“我将要离开郑州前往北京”,只有当我们连续地处理“离开郑州”和“前往北京”时才能分辨郑州和北京这两个地名到底哪个是出发地哪个是目的地。这就是建立循环神经网络(RNN)的目的:处理序列数据(如文本、语音、时间序列)。
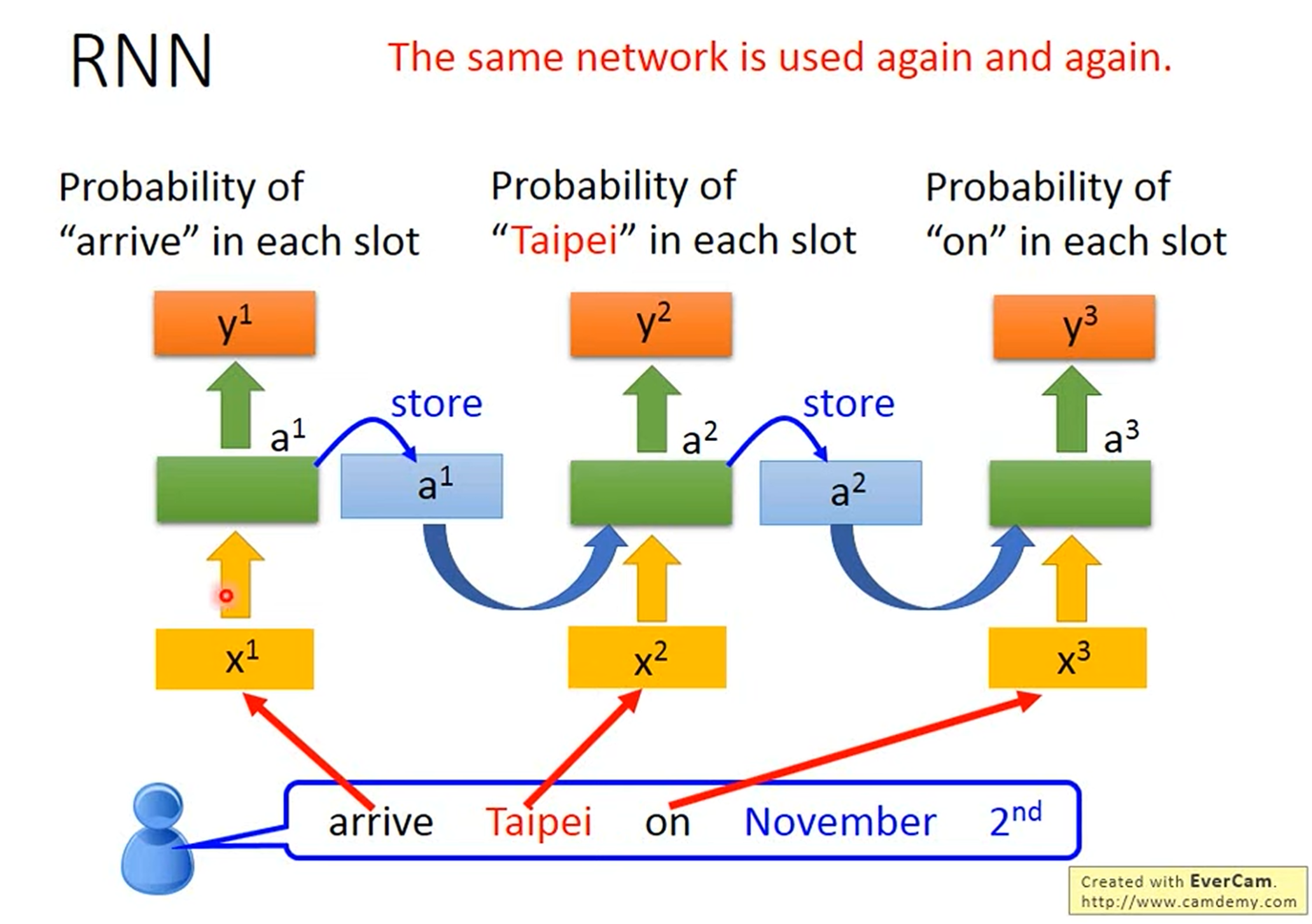
如图所示,RNN在处理信息时会将上一次的输出专门存进一个Memory当中,这个记忆单元将连同下一次的输入一起继续进行运算。这样一来就实现了记忆性。
三、长短期记忆网络 (Long Short-Term Memory, LSTM)
但是RNN的一个显著的问题就是其对长期信息的读取十分困难,因为这需要它多次连续相乘。尤其是当序列较长时,早期时间步的梯度会变得极其微弱,使得模型无法有效更新这些位置的权重,从而遗忘远距离的信息。所以人们就设计出了一种更加科学的机制,即长短期记忆网络(LSTM)。
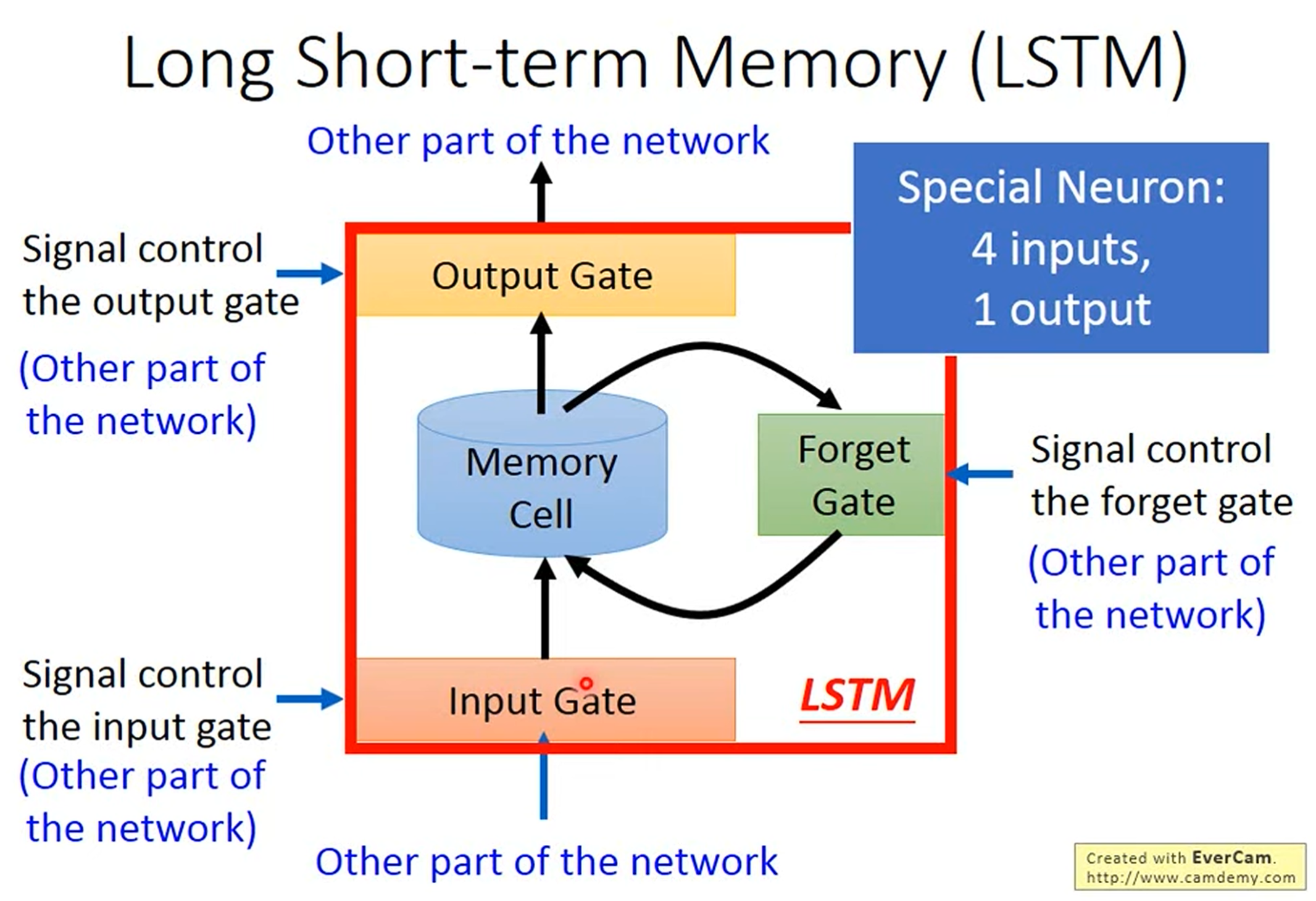
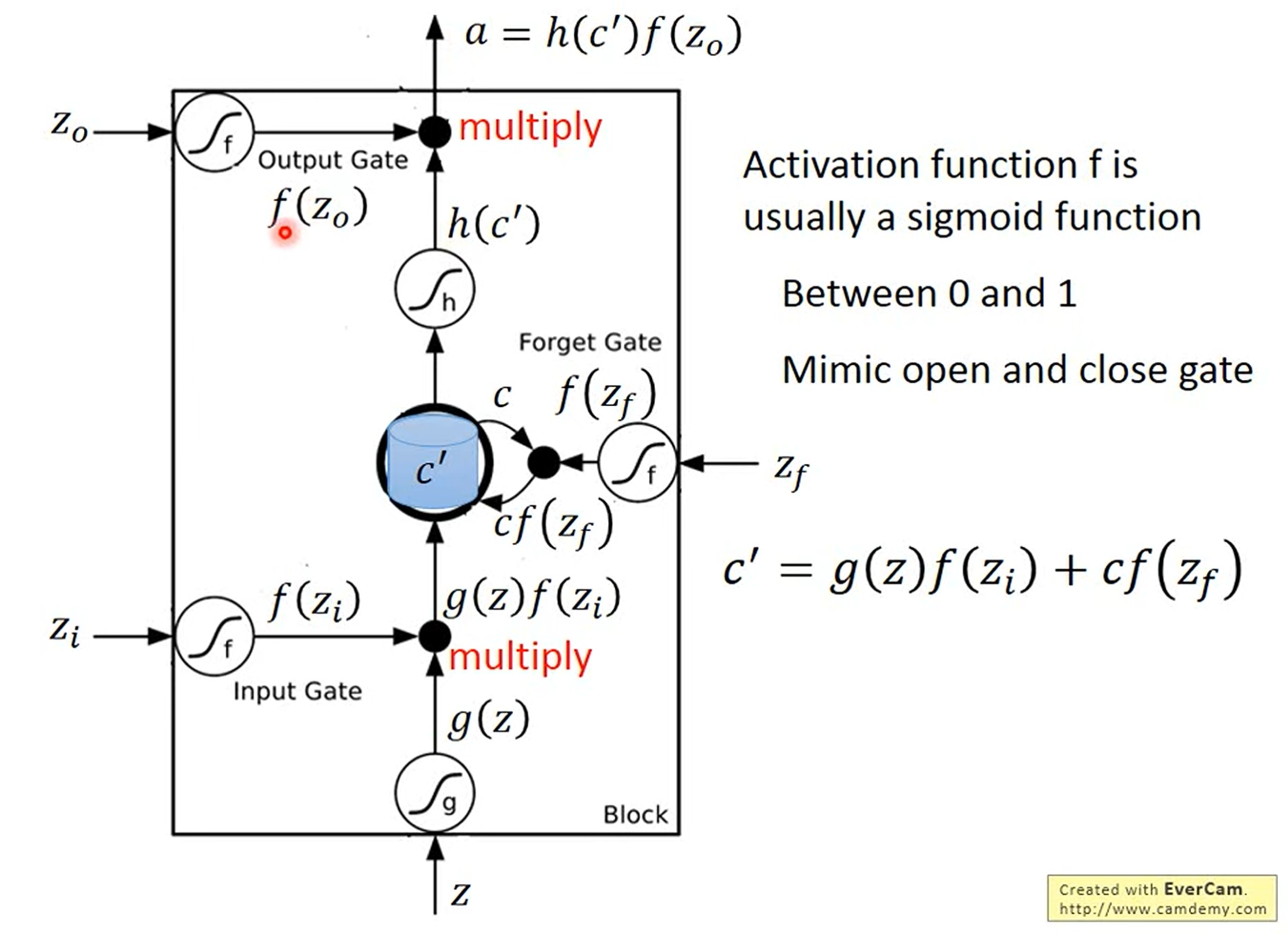
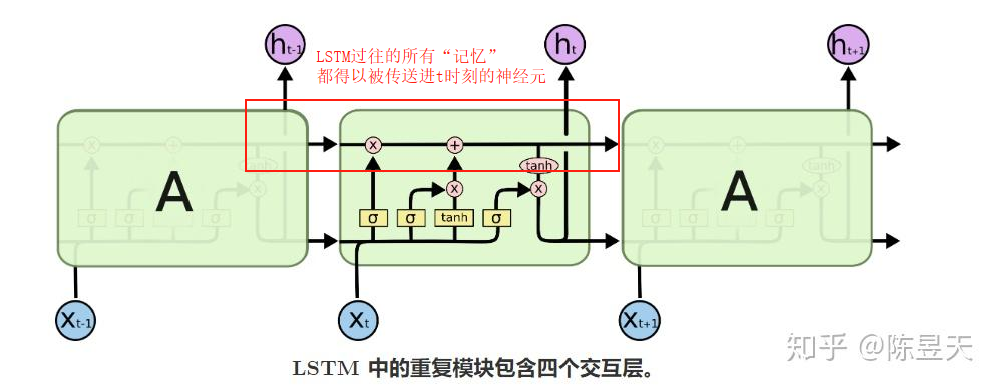
如图所示,LSTM通过引入门控机制来实现对信息的动态控制,即输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate),其具体控制机制如下图所示。
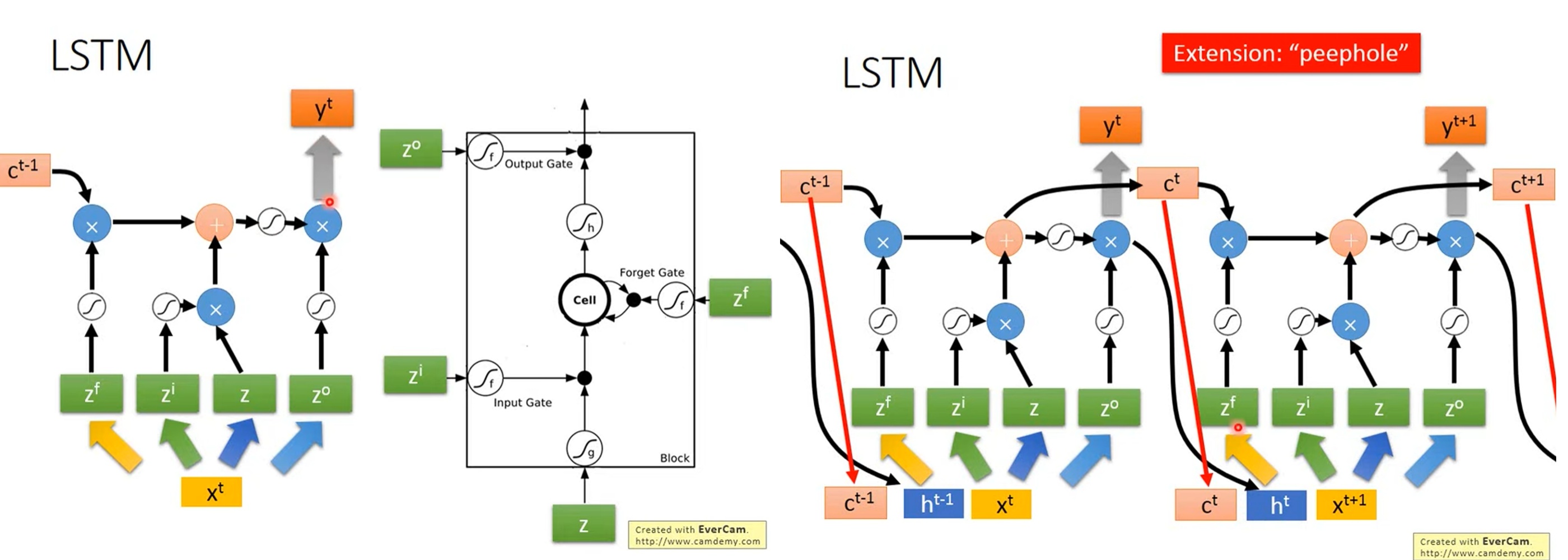
那么下面几幅图展示了LSTM的连续处理机制,其中第t-1次的输出和第t次的输入将一同构成新的输入向量参与运算。这两部分会分别通过不同的权重矩阵进行线性变换,然后将结果相加(或拼接后乘权重矩阵)来匹配LSTM的内部维度。而之前的所有神经元的“记忆”信息也将被传送进t时刻的神经元当中。
四、图神经网络 (Graph Neural Network, GNN)
恰如其名,图神经网络(GNN)主要用于处理具有图结构数据的场景,能够有效捕捉节点间的复杂关系和拓扑信息。基于处理图数据的方法和理论基础,GNN有两种主要的处理方法:基于空间(Spatial-based)和基于谱(Spectral-based)。
1. 基于空间
基于空间的核心思想是直接在图的拓扑结构上进行计算,通过聚合(aggregation)邻居信息来更新结点表示。比较主流的基于空间方法有以下几种:
1)GraphSAGE(Graph Sample and AggregatE)
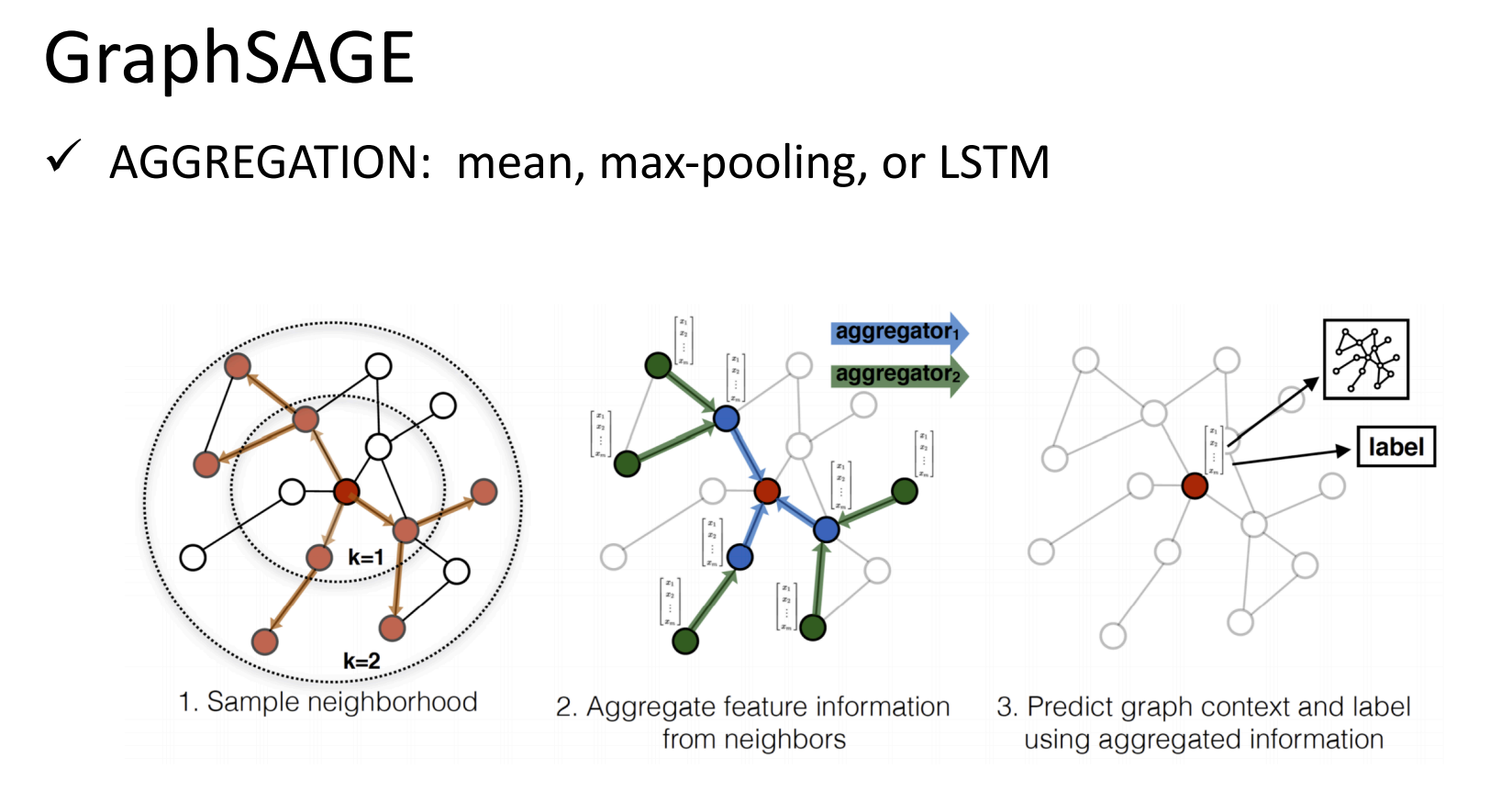
GraphSAGE的核心思想是通过邻居采样和聚合函数分别来解决大规模图计算问题和结点嵌入的生成。其具体过程如上图所示:
- 邻居采样(Sample Neighborhood):传统的GNN会要求聚合所有邻居,在大样本的情况下这显然会严重浪费算力。那么此方法的思路就是像街头采访一样在每一层只采样固定数量个邻居(图中的
k=1和k=2表示的是采样深度)。 - 特征聚合(Aggregate Neighbor Info):在上一步的邻居采样之后,GraphSAGE会将所有采样到的邻居信息聚合成一个向量,聚合方法任选
Mean、Max-Pooling、LSTM等皆可。 - 预测与更新(Predict & Update):最后根据自身特征和聚合到的邻居信息就能生成新的嵌入。
2)GAT (Graph Attention Networks)
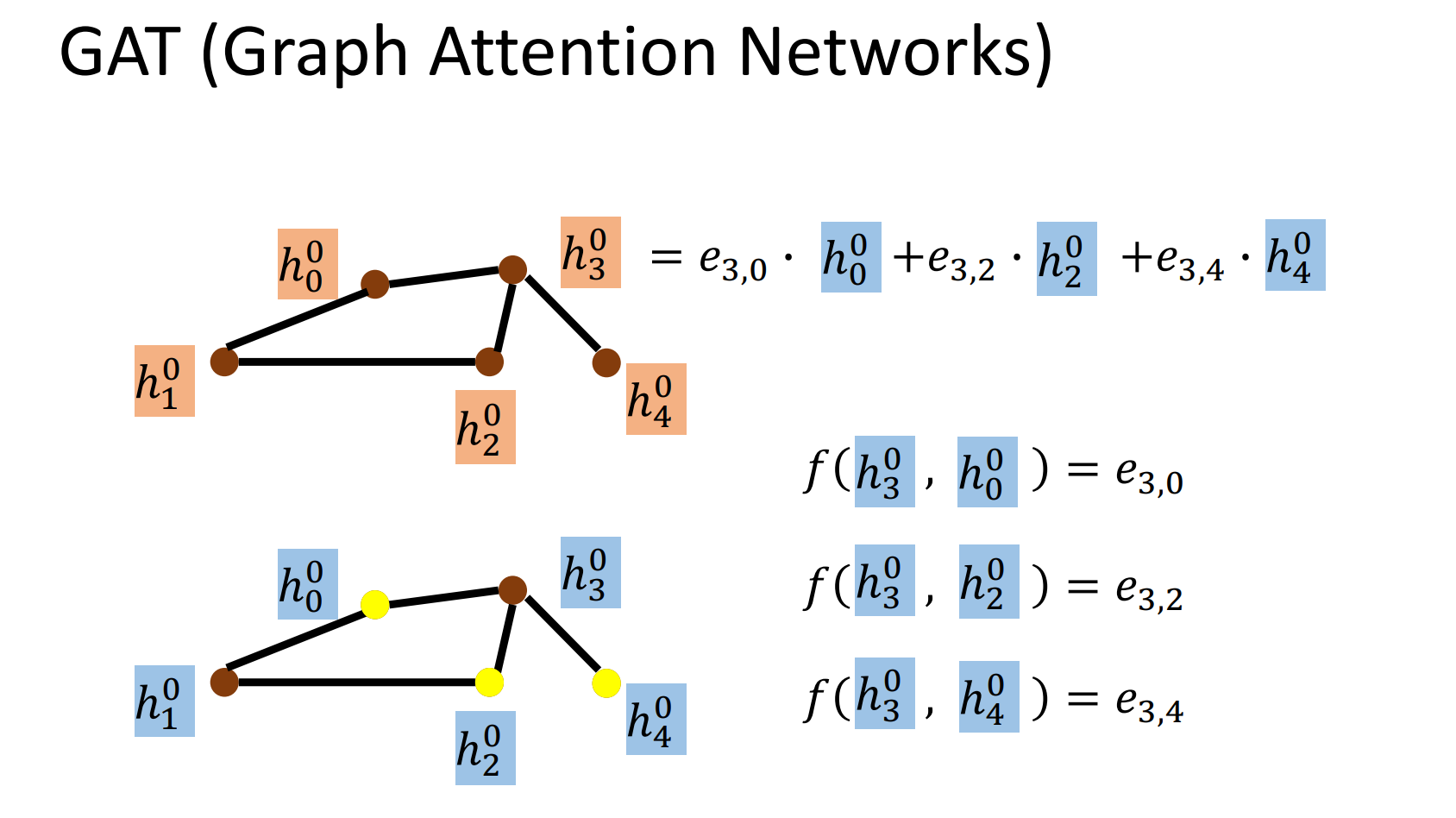
首先,GAT中的每个结点会检查自己和邻居之间的“注意力”,如图中以为例,使用了一个小型神经网络f计算得出了它和三个邻居之间的e(energy)。并以此为基础,使用注意力权重对邻居特征加权求和,进而更新,使其既保留自身特征,又吸收了关键邻居信息。
2. 基于谱
基于谱的图卷积神经网络利用图信号处理中的谱理论(图的拉普拉斯矩阵特征分解)来定义图卷积,将图数据转换到谱域进行滤波操作。其数学理论非常严谨且复杂,但是在效率和灵活性上都远远不及基于空间的GNN,因此这里我们先只做了解。